Method
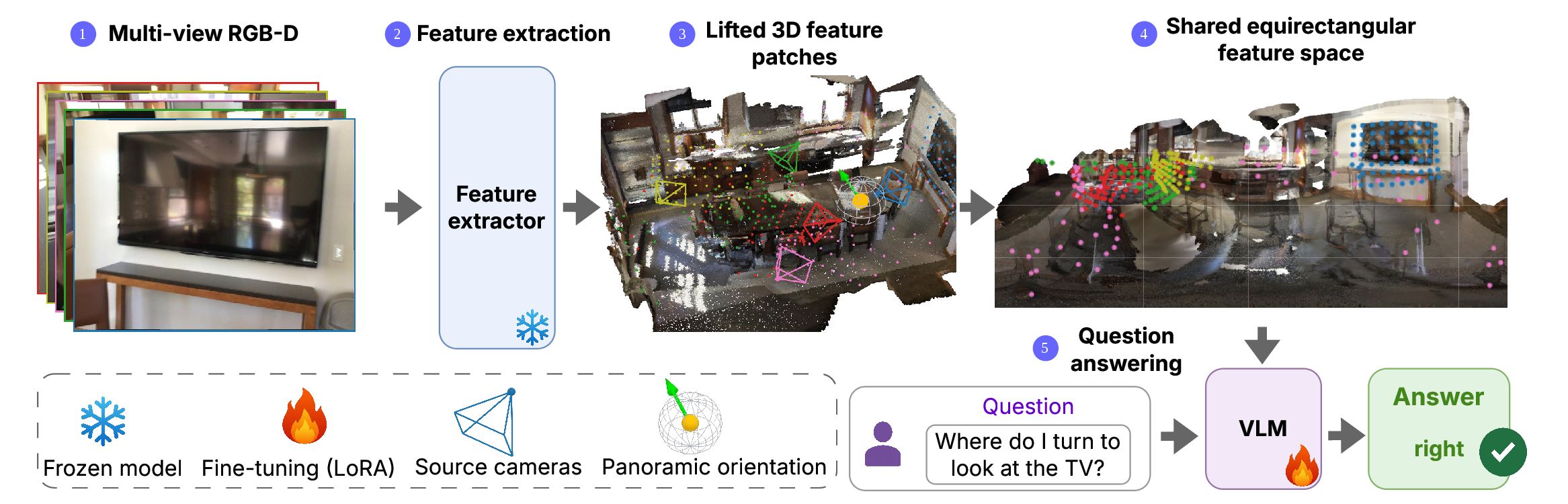
Feature extraction and 3D lifting. Each input image is passed through the frozen vision encoder of a pretrained VLM to obtain per-patch features. Each patch is unprojected to world coordinates using its metric depth and the camera-to-world pose.
Panoramic canvas. Each lifted patch is placed on the canvas at the continuous longitude and latitude of its 3D position as seen from a chosen origin. Positions are continuous, so every patch becomes its own token rather than being rasterized onto a shared pixel grid and collapsed by a hand-designed reduction rule. The VLM then consumes the canvas through its native attention layers, with each patch's spherical coordinates on the spatial position axes and its source-frame index on the temporal axis.
Interactive Demo
Pick a situated question to fly the canvas-origin globe to that viewpoint. Every lifted patch feature reprojects onto the globe along a spoke colored by its source camera, and the strip below shows the same reprojection unrolled into the equirectangular canvas the VLM actually consumes. Drag to orbit.
Equirectangular canvas from the current viewpoint. Forward is centered (green crosshair). Dots are lifted patch features colored by source camera.
Two-Stage Training
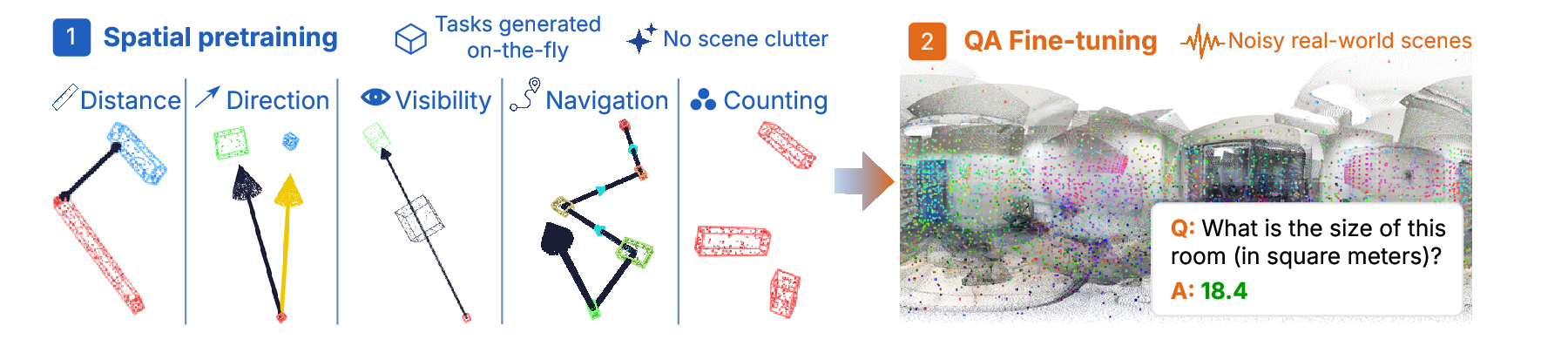
Stage 1: spatial pretraining. A LoRA adapter and the 3D position embedding are trained on an on-the-fly curriculum of spatial reasoning tasks. Each sample places real-image patch features at procedurally chosen 3D positions on an otherwise empty canvas. With appearance decoupled from size and location, geometry on the canvas is the only signal that can solve the task.
Stage 2: target adaptation. The stage-1 adapter is merged back into the base language model, and a fresh, lower-rank adapter is trained on a mixture of downstream spatial question answering. The merged stage-1 update anchors the geometric reading while the smaller stage-2 adapter handles answer-format adaptation.
Video
Results
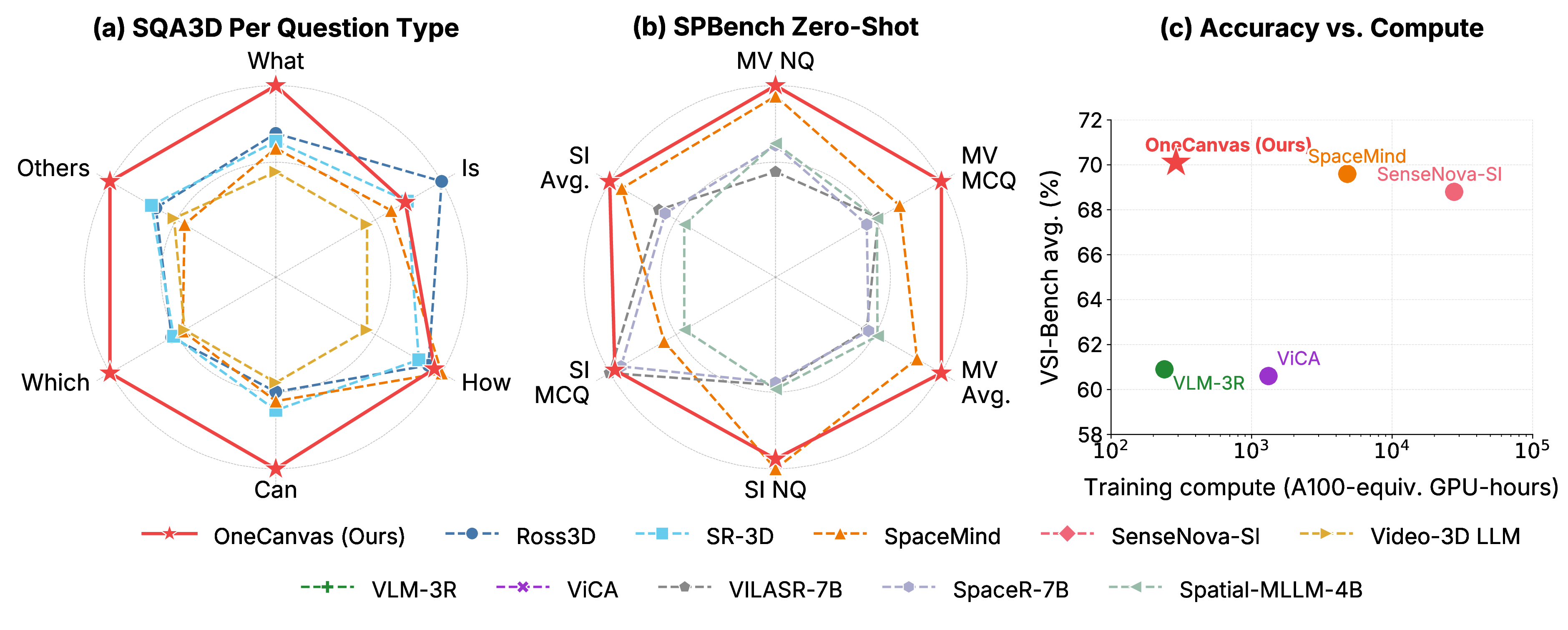
OneCanvas reaches state of the art on three spatial reasoning benchmarks: SQA3D (65.3 EM@1, 2.3 points above the previous best), VSI-Bench (70.1 average), and SPBench (72.1 zero-shot overall, 4.8 points above the next best method), while using an order of magnitude less training compute than the strongest competing methods.
SQA3D
65.3
EM@1
+2.3 over prev. SOTA
VSI-Bench
70.1
Average
+11.3 on route planning
SPBench
72.1
Zero-shot overall
+4.8 over prev. SOTA
BibTeX
@misc{baranowski2026onecanvas,
title = {OneCanvas: 3D Scene Understanding via Panoramic Reprojection},
author = {Baranowski, Bart{\l}omiej and Chen, Dave Zhenyu and Nie{\ss}ner, Matthias},
year = {2026},
eprint = {2606.19253},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}